There are still a vast number of Hospitals in India where the Vitals monitors are not synced to some cloud. Modern machines do come equipped with that functionality, though. The objective of the Vitals Extraction Challenge, Inter IIT Tech Meet 11.0 hosted by IIT Kanpur, was to To extract Heart Rate, SPO2, Respiration Rate, Systolic Blood Pressure,
Diastolic Blood Pressure and MAP from images of ECG monitors
To extract and digitize the heart rate graph from the ECG monitor images.
Approach
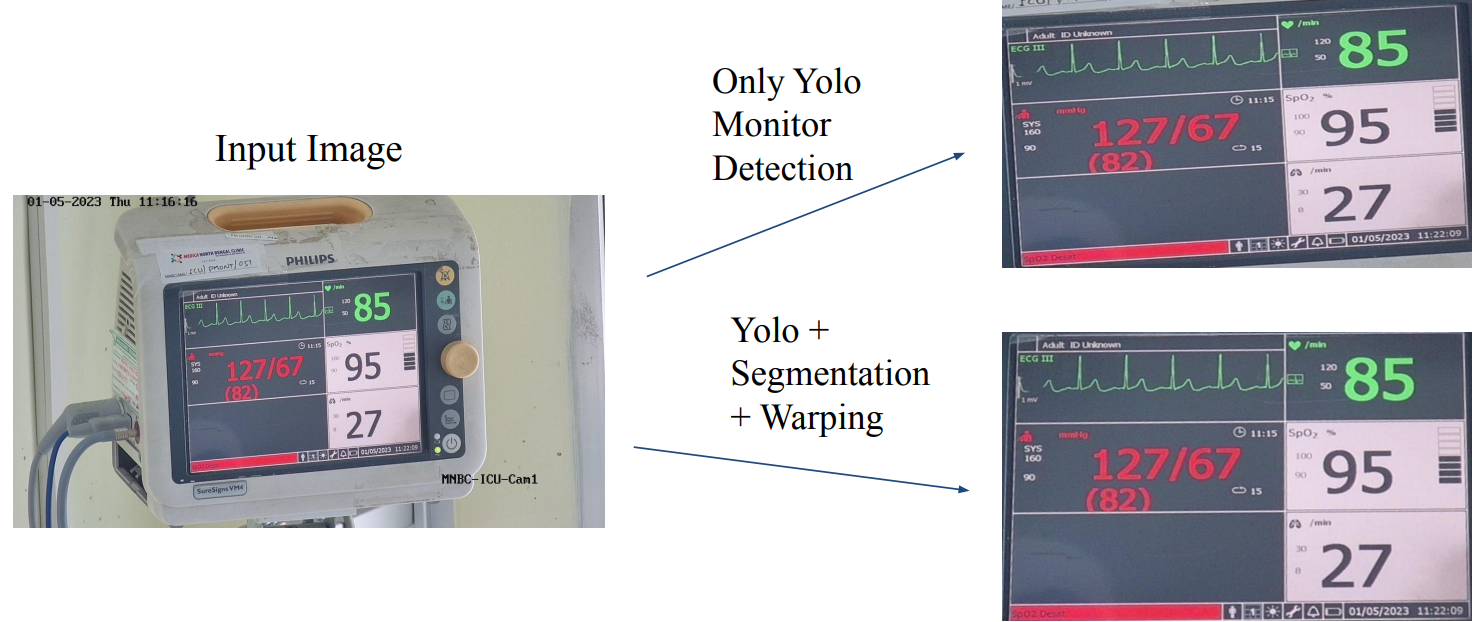
- Extracting warped and enhanced screens from raw images to better capture the vitals.
- Using object detection model trained on manually curated dataset to differentiate between different components of the screen.
- Employing OCR to extract the vitals from multiple objects detected from the screen and digitizing the HR graph.
Methods utilized
- YOLO v7: Used for Object detection (both monitor and screen components)
- UNet (Encoder backbone: ResNet34): Used for semantic segmentation
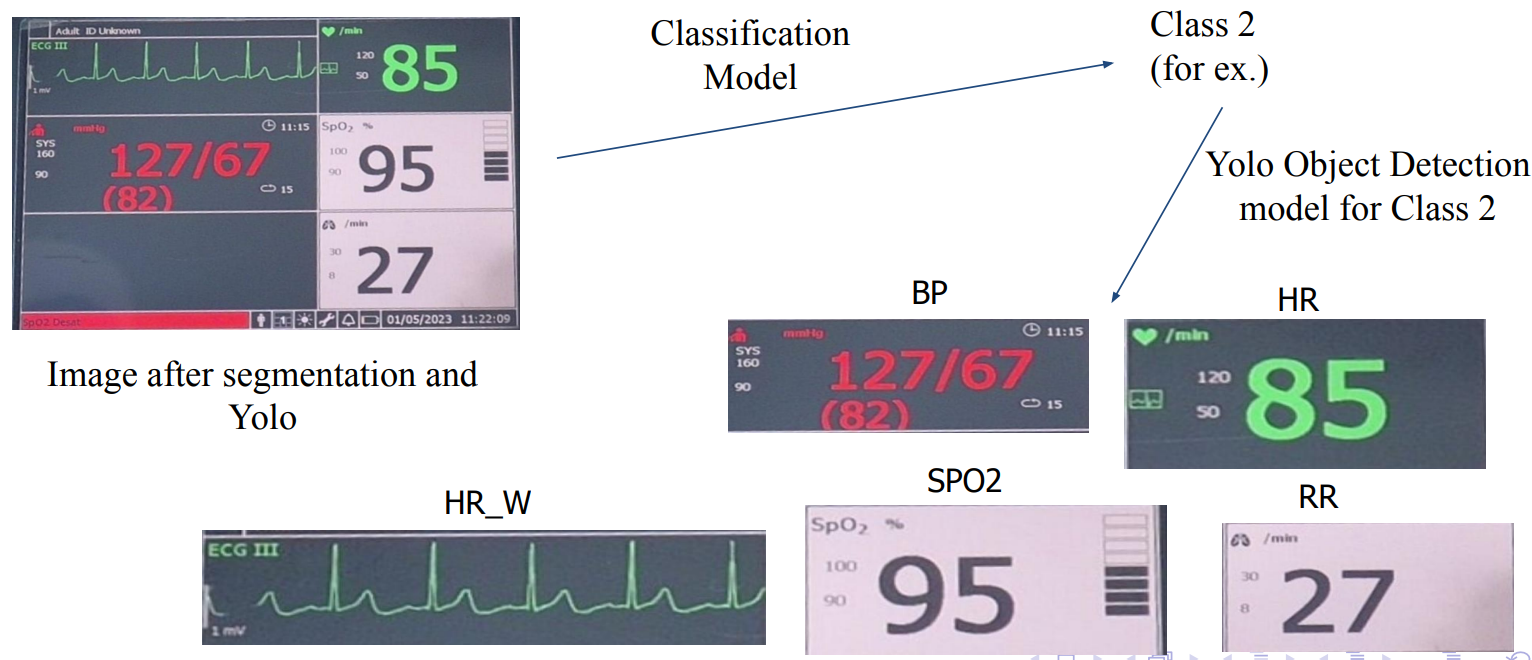
- ResNet50 (transfer learning): Used for monitor classification
- Paddle OCR: Used for extracting vitals from extracted monitors
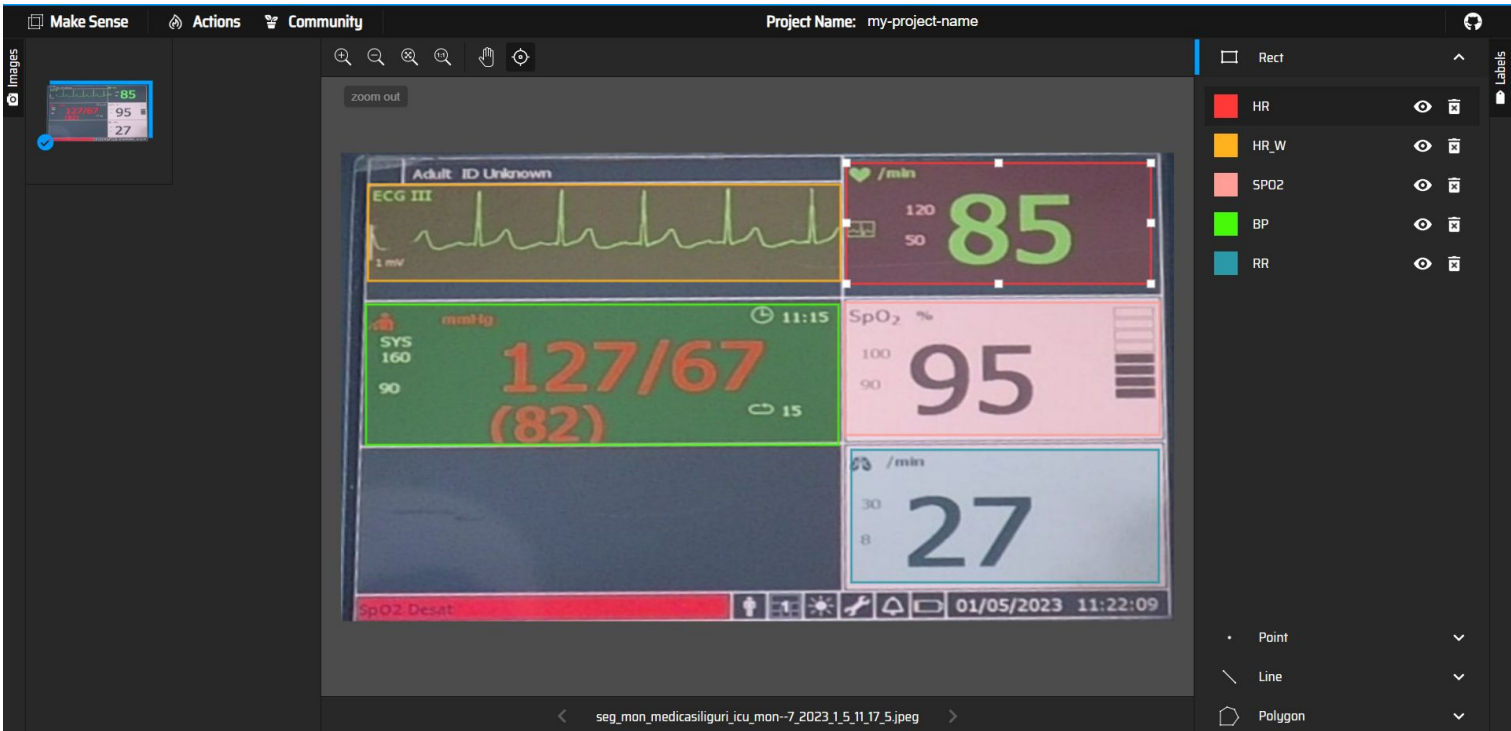
makesense.ai was used for annotating the images in the unlabelled dataset.
A total of about 1584 images were employed for training the YOLOv7 models and
segmentation model for screen extraction.
For object detection, around 400 images were used to train each YOLOv7.
The following is a snapshot of the annotating process on the website:
Workflow
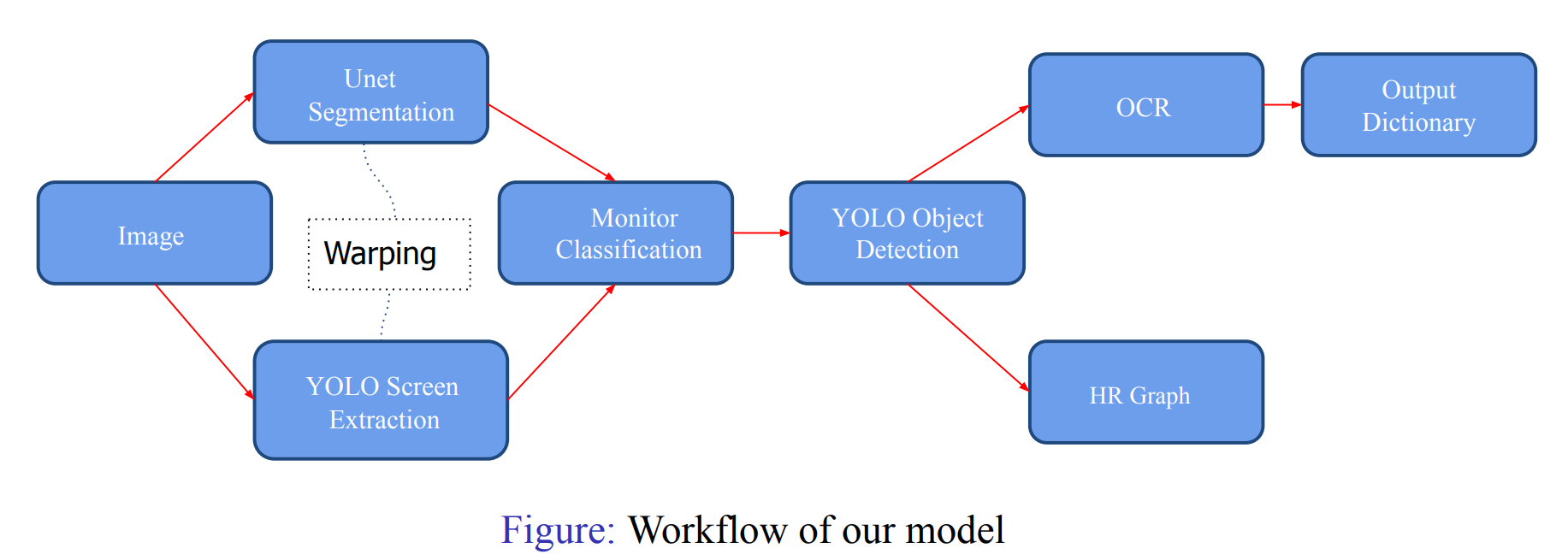
Extracting Screens [UNET + YOLO]
- An intricate combination of semantic segmentation and YOLO screen detection extracts warped screens for further processing.
- UNET architecture with resnet-34 encoder architecture was trained using transfer learning on the dataset provided by the Cloud Physician company.
- YOLOv7 is a fully connected neural network based architecture with the typical head, body and neck components. We used the yolov7-tiny model, which has around 6 million trainable parameters, for fast and accurate inference.
- Using the Bounding boxes from YOLO V7 and semantic segmentation masks from UNet model to accurately and precisely extract corners of screen from monitors
Why not Simply use UNET?
- Multiple Corner Problem:
- We take the predicted masks from segmentation model which have hazy and unclear edges and process them to estimate a polygon. The polygon is obtained in form of vertex coordinates.
- We use the coordinates of the polygon to warp the tilted or sheared screens to obtain rectangular cut-outs which appear as if photo were taken right from the front. Hence we Change the Perspective to obtain better results from OCR models.
- With an IoU>0.9, the segmentation model was great, but even slight inaccuracy in mask prediction resulted in multiple corner getting detected, due to which warps were unsatisfactory in around 43% of the images.
- Using tilted or sheared images, were giving wrong outputs while digitizing the extracated the points.
- Solution:
- Using the corners from YoLo Bounding Boxes to estimate the exact 4 corners with high confidence from the multiple corners of mask.
- For every corner of bounding box, we find the nearest polygon corner. Using this we obtain the best 4 / multiple detected vertices
- We further use those 4 vertices to warp the angled screen
Monitor Classification
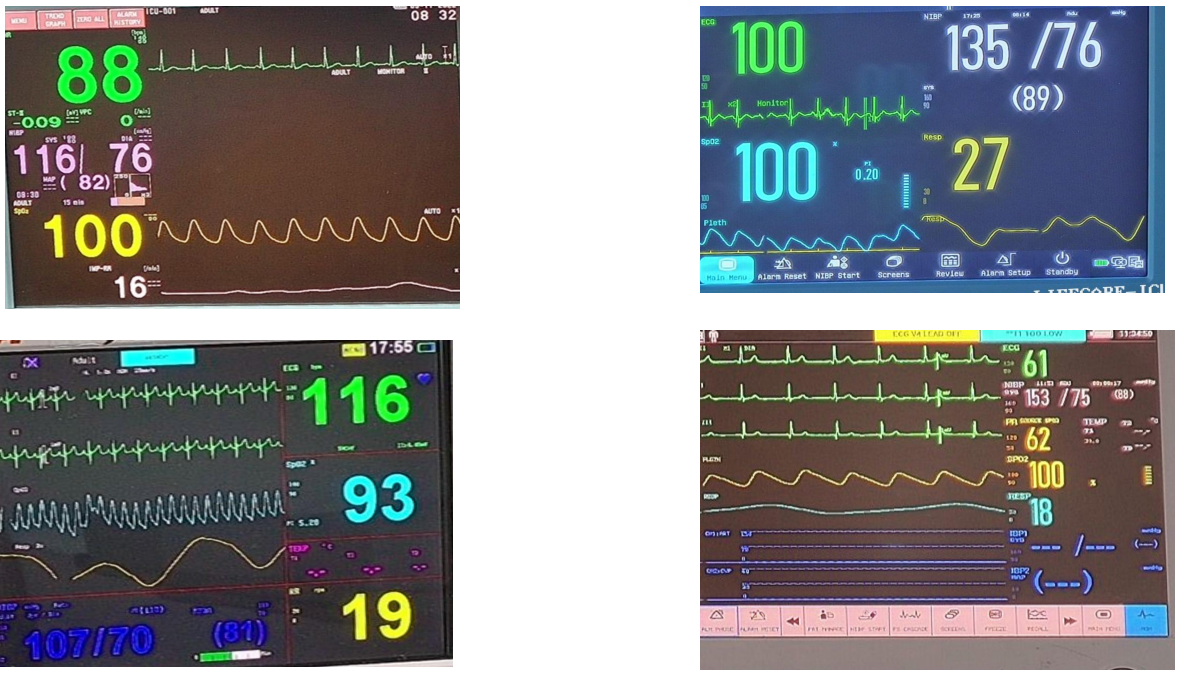
- Monitors were classified based on the given dataset into four classes using a ResNet50 based classification model using the Classification_Dataset provided by the problem curators.
- Dataset size: 4 classes with 250 images each
- Further processing on these classified monitors using Yolo and OCR.
There were four different types of monitors:
Component Detection Using YOLO
- Manual annotations were done using the makesense.ai website, afterwhich, we obtained the images and their corresponding annotations text file in the required YOLO format.
- 2 types of yolo models were trained - one, for screen extraction from a far off image of the monitor and the other, for component detection inside the screen.
- For the screen extraction, the final layer was added such that it predicted only one class and the for the other yolo models, there were 5 output classes.
- Once the classification model, classified the screen type, the yolo model trained for that type was used to predict the component bounding boxes.
- The output of the yolo model were bounding boxes of different classes. This output was passed directly to the OCR function such that the final result is returned.
Text Recognition: Paddle OCR + Filters
- Character recognition was performed on the objects detected from monitors with the help of PaddleOCR.
- The requirement of the OCR model being fast and accurate was met by Paddle OCR a text recognition model based on algorithms like DB and CRNN.
- But PaddleOCR also detected unnecessary texts from every object, requiring
further post processing.
- Solution:
Custom filters designed by manual inspection and analysis of the OCR outputs. Checking the ratio of area of biggest recognized number by size with area of bounding box. The sanity of recognized text is further checked through regex. Reducing false positives using non max suppression and other filters
- Solution:
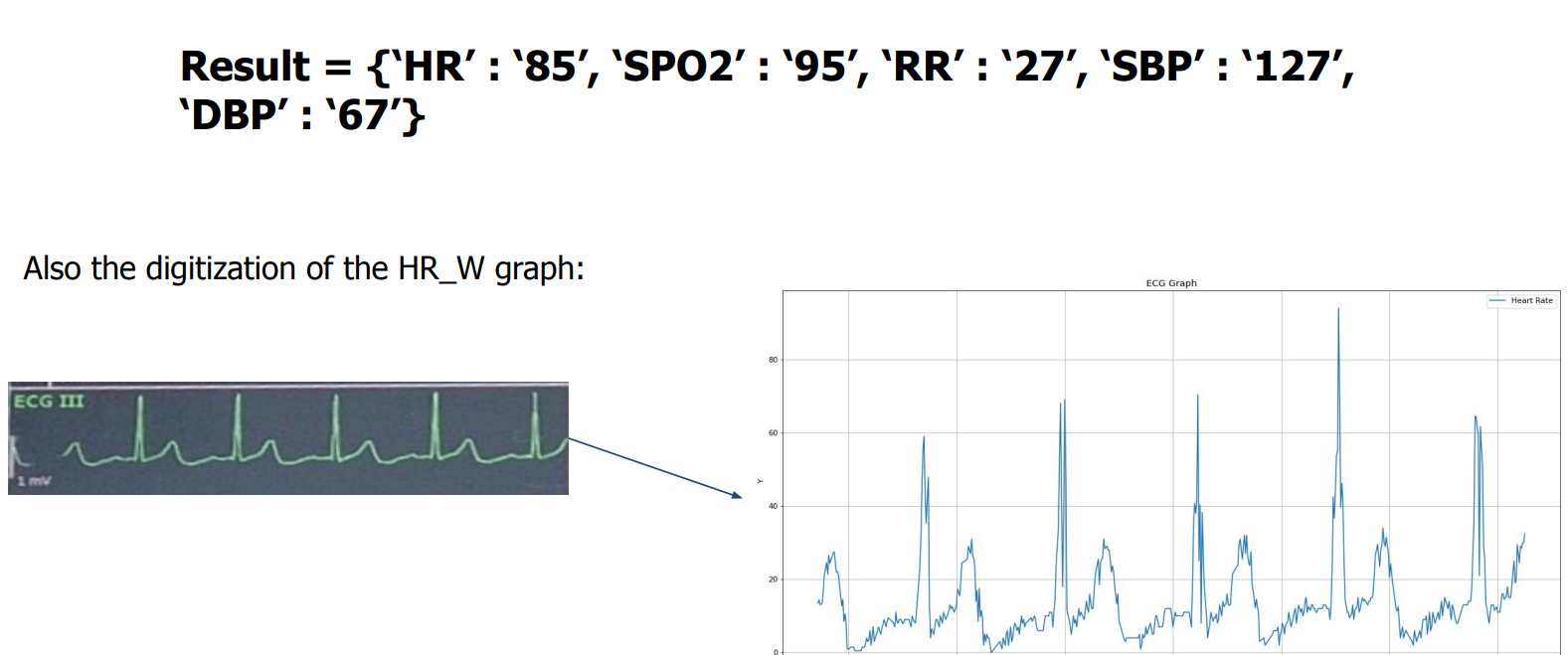
Graph Digitization
- The extracted HR graph using the YOLO models is fed to the
create_graph_from_imagefunction - The function first converts the image into a grayscale images and then uses thresholding to output a binary images.
- The function then finds the contours using using opencv library
- The resultant graph is a double-edged plot for majority of the images, hence the mean of both the edges was taken to be the final graph
- The function then displays the plot using matplotlib and also returns the data points.
Results: